reflecting on two conferences
Background
At the start of this semester, I began working as an Undergraduate Research Assistant (URA) in the Virginia Tech Department of Computer Science. Through this role, I am engaged in two distinct research projects. This blog post will focus on my work with Dr. Sehrish Basir Nizamani , an Assistant Professor in the Department of Computer Science. In December 2024 – over winter break – I reached out to Dr. Nizamani because I found her research in Human-Computer Interaction (HCI) fascinating.
During our initial conversation, she expressed her interest in researching if Large Language Models (LLMs) could be harnessed to identify usability flaws in web and mobile applications. Her preliminary research was centered around how LLMs could identify usability flaws in Low Fidelity and High Fidelity models seen here. She explained how her research was centered around looking at how LLMs can use image processing to identify usability flaws in these specific models. LLMs would be prompted to conduct a usability evaluation given screenshots of a website or mobile application. The model would also be prompted to conform specifically to Jakob Nielsen’s 10 Usability Heuristics. However, I brought up the idea of researching if LLMs could be used to identify usability flaws at the development stage of applications. In other words, I was curious if LLMs could detect potential usability flaws while an application or website was being built. Traditionaly, applications can’t be tested for usability flaws until a final product or prototype is developed. If we could effectively leverage LLMs to identify usability flaws at the development stage, we could be uncovering a potentially groundbreaking idea in Human-Computer Interaction that would drastically reduce lead time on application and web development.
After proposing this idea, Dr. Nizamani also became very interested in the potential of this research with regard to the HCI field. Shortly after starting my initial work on the project, another undergraduate researcher – Ethan Luchs – joined me. He has been an invaluable member of our research discoveries thus far.
Literature Review
To approach this project, we first began with a literature review. We needed to have a thorough understanding of usability testing, with specific regard to LLMs. Thus, we conducted a thorough review of scientific research papers related to HCI and usability testing. We also needed to ensure that our idea was unique (i.e. it has not been previously published in a research paper). We found that there was very limited use of LLMs in HCI research, and even less use with regard to usability testing.
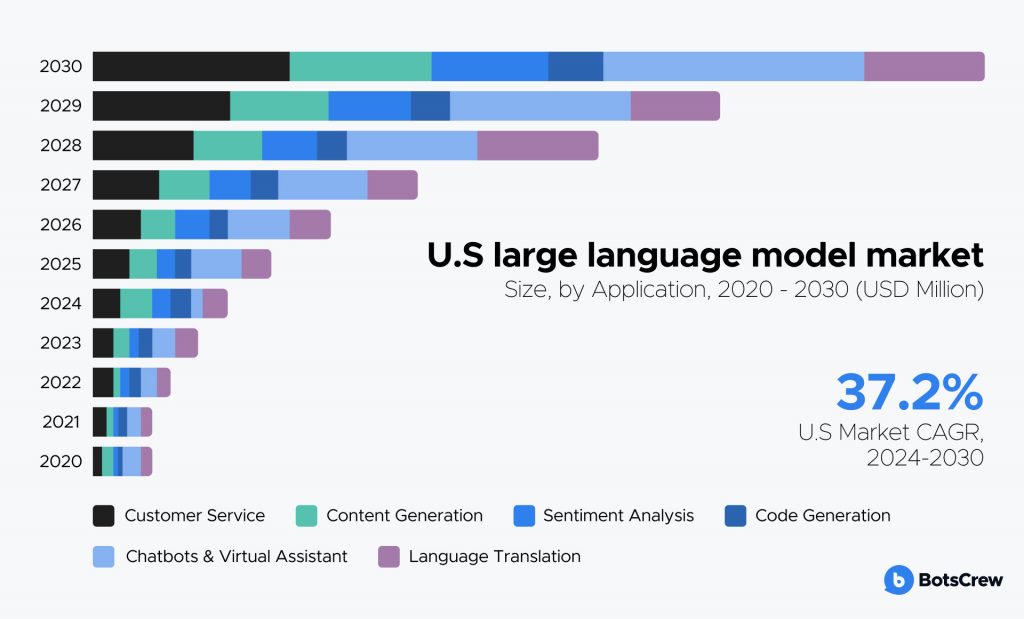
As seen in this bar graph representing the U.S. large language model market, there is very limited usage of LLMs in HCI research. The graph underlines how the majority of LLM usage is centered around code generation and debugging, rather than actually detecting and identifying usability concerns. This agrees with what we found in our literature review, thus further motivating us to explore this concept.
Research
After conducting a thorough literature review, we were prepared to begin our research. We started by writing an abstract for a preliminary version of our paper. After refining it dozens of times, we submitted the abstract to the 2025 CAPWIC Conference, a conference run by the prestigious Association for Computing Machinery (ACM). We also submitted our abstract to the Center for Human-Computer Interaction Big Idea Showcase. We were eventually accepted to present our preliminary research at both.
We began preparing for the conferences well in advance. To ensure we collected both accurate and precise data, we adhered to a systematic research methodology:

This flow chart represents our research methodology; as discussed, we began with a literature review of papers related to HCI and usability evaluations. We then began to identify websites that we would use for our preliminary data for the two conferences. To ensure we adhere to ethical research standards, we agreed to select websites that are strictly open-source (e.g. GitHub repositories) We picked a total of ten websites, all of which were different frameworks (e.g. basic HTML, React.js, Vue.js, Django, etc). To get a more accurate representation of our data, we approached our evaluations using Inter-Reliability Rating (IRR). Using IRR allowed us to get an understanding of the consistency of our evaluations. To do this, I would have an LLM perform evaluations on five websites, and then Ethan would perform evaluations - with the same prompt and websites - during a different period of time. By having the same LLM perform evaluations on the same five websites, we are able to cross-check the data that the LLM fed back to us, thus allowing us to check consistency with respect to time. We then did the same method for the remaining five websites.
With our collected data, we then used a computational model to calculate the Kripendorff’s Alpha, the fraction of issues found, and the fraction of recommendations created.
Kripendorff’s Alpha: .107
Fraction of Issues Found: 86%
Fraction of Recommendations Created: 80%

Our Kripendorff’s Alpha value of 0.107 suggests that the consistency of our dataset is not any better than randomness. While that may seem negative to our research, it is very important to consider its meaning with respect to our topic as a whole. This only means that the model is identifying different usability issues for the same website during two distinct evaluations; it does not mean that it is identifying incorrect usability issues. This is furthered with our two fraction calculations – the LLM is finding valid issues 86% of the time, and is generating correct recommendations (i.e. suggestions for how the issue can be fixed) 80% of the time. Thus, it is important to notice that, for the majority of the time, the LLM is consistently identifying valid issues and generating valid recommendations. In our case, the calculated Kripendorff’s Alpha simply suggests the LLM is identifying different, but still correct, usability issues with the same website when two different evaluations are compared.
Looking Ahead
Most importantly, we want to find ways to improve an LLM’s ability to consistently identify the same usability flaws for the same website (i.e. same snippet of code). While we are still in the early stages of research, we believe that creating a dedicated pipeline for a LLM based specifically for usability evaluations would significantly improve our Kripendorff’s Alpha. This would mean taking a pre-existing LLM, and constructing a pipeline so that for every session, the model is already aware of pre-existing conditions, knowledge, and requirements for usability evaluations of code snippets. This way, the model would be utilizing the same knowledge, approach, and rules for every single website it evaluates.
Acknowledgements
My trip to CAPWIC was not possible without the support from the Virginia Tech Department of Computer Science. Both myself, other undergraduate researchers, and Ph.D candidates received a fully-funded trip, including transporation, meals, and hotel accommodations. I am immensely grateful to the CS department for investing in us and our research - it truly underscores our department’s dedication to research. A special thanks to the Department of Computer Science Department Head, Dr. Christine Julien , for supporting us along the way and ensuring the event was a success. And, of course, thank you to Dr. Sehrish Basir Nizamani for the guidance and support throughout this semester - this project would have never happened without you! I’d also like to thank the various other CS professors who attended the conference and supported us along the way: Dr. Scott McCrickard, Dr. Jin-Hee Cho, Dr. Mohammed Seyam, and Dr. Melissa Cameron.
Enjoy Reading This Article?
Here are some more articles you might like to read next: